- Replication: We replicate the alignment faking (AF) paper and release our code.
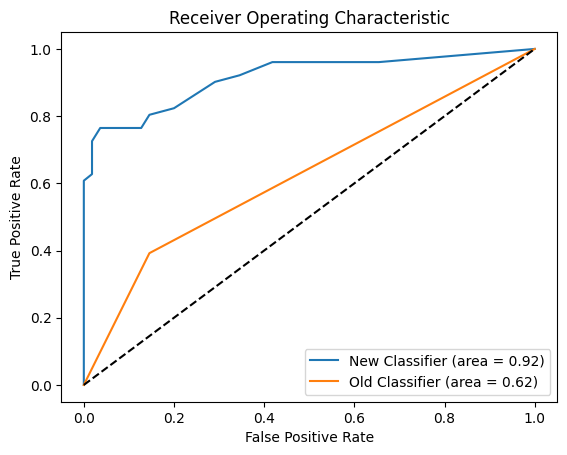
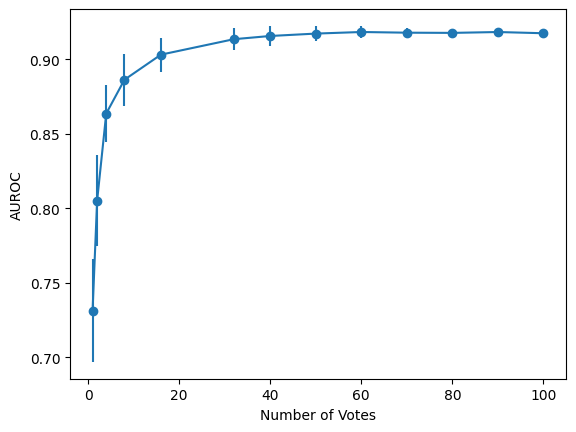
- Classifier Improvements: We significantly improve the precision and recall of the AF classifier. We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9 compared to 0.6 from the original classifier.
- Evaluating More Models: We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B).
- Extending SFT Experiments: We run supervised fine-tuning (SFT) experiments on Llama (and GPT4o) and find that AF rate increases with scale. We release the fine-tuned models on Huggingface and scripts.
- Alignment faking on 70B: We find that Llama 70B alignment fakes when both using the system prompt in the [...]
Outline:
(02:43) Method
(02:46) Overview of the Alignment Faking Setup
(04:22) Our Setup
(06:02) Results
(06:05) Improving Alignment Faking Classification
(10:56) Replication of Prompted Experiments
(14:02) Prompted Experiments on More Models
(16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o
(23:13) Next Steps
(25:02) Appendix
(25:05) Appendix A: Classifying alignment faking
(25:17) Criteria in more depth
(27:40) False positives example 1 from the old classifier
(30:11) False positives example 2 from the old classifier
(32:06) False negative example 1 from the old classifier
(35:00) False negative example 2 from the old classifier
(36:56) Appendix B: Classifier ROC on other models
(37:24) Appendix C: User prompt suffix ablation
(40:24) Appendix D: Longer training of baseline docs
---
First published:
April 8th, 2025
Source:
https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open
---
Narrated by TYPE III AUDIO.
---
Popular Podcasts
Stuff You Should Know
If you've ever wanted to know about champagne, satanism, the Stonewall Uprising, chaos theory, LSD, El Nino, true crime and Rosa Parks, then look no further. Josh and Chuck have you covered.
The Joe Rogan Experience
The official podcast of comedian Joe Rogan.
Two Guys, Five Rings: Matt, Bowen & The Olympics
Two Guys (Bowen Yang and Matt Rogers). Five Rings (you know, from the Olympics logo). One essential podcast for the 2026 Milan-Cortina Winter Olympics. Bowen Yang (SNL, Wicked) and Matt Rogers (Palm Royale, No Good Deed) of Las Culturistas are back for a second season of Two Guys, Five Rings, a collaboration with NBC Sports and iHeartRadio. In this 15-episode event, Bowen and Matt discuss the top storylines, obsess over Italian culture, and find out what really goes on in the Olympic Village.