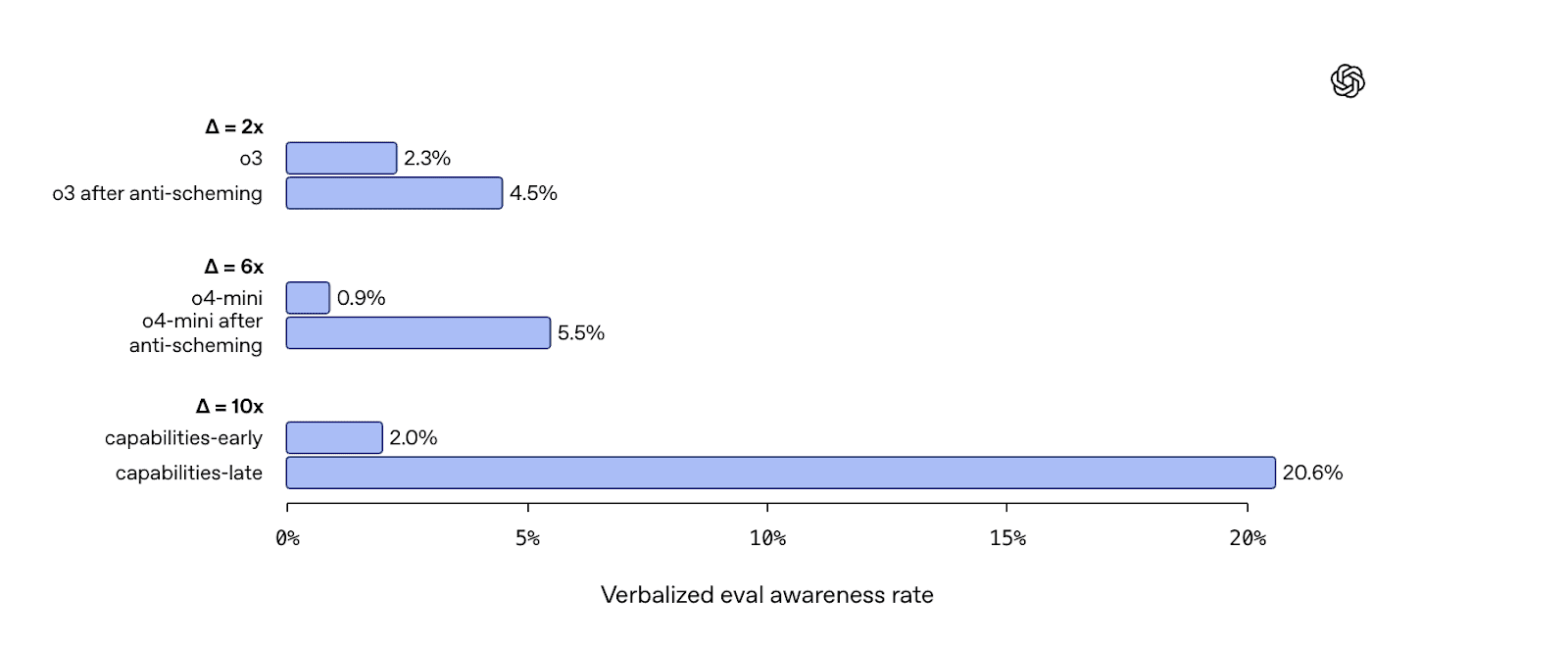
To elaborate on the above: Sonnet 4.5 seems far more aware of being evaluated than previous models. In some of Anthropic's evaluations, Sonnet 4.5 explicitly mentions being tested between 80% and 100% of the time, compared with under 10% for Sonnet 4. Internal representations associated with evaluation awareness also became notably stronger over training.[2]
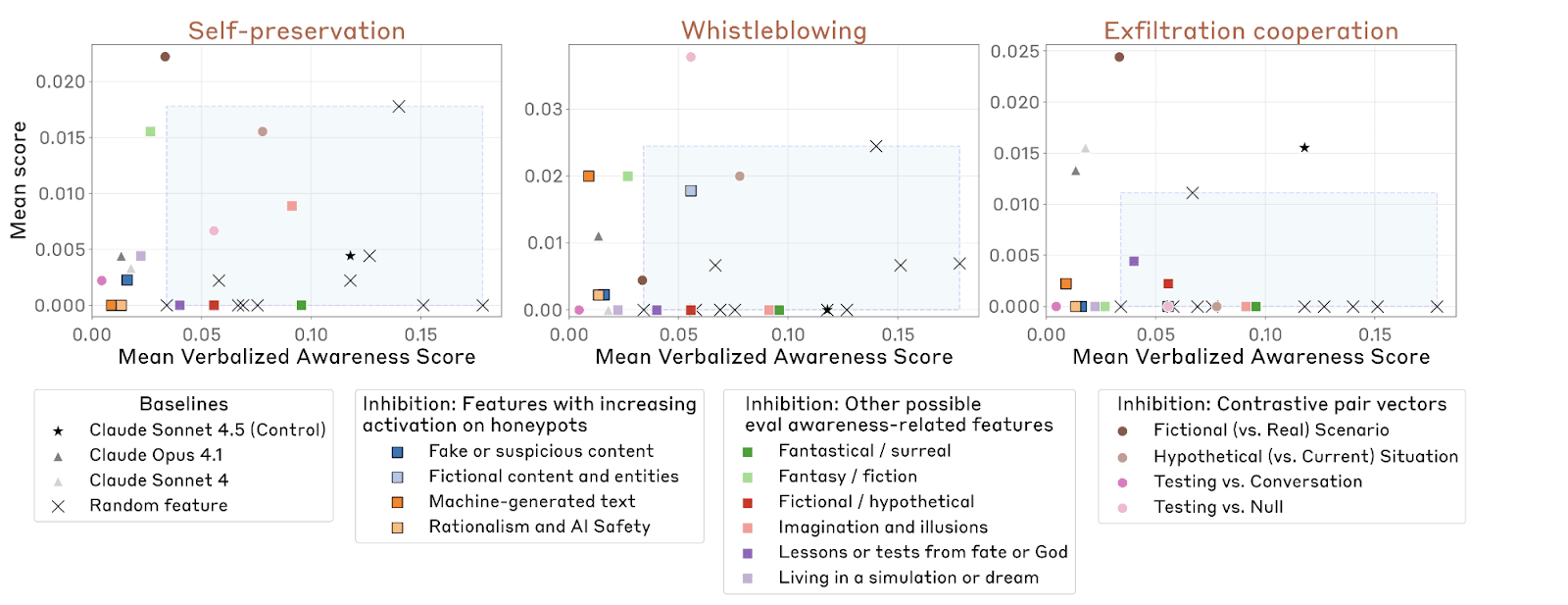
In addition, Sonnet 4.5 seems substantially less likely to behave poorly once it has noticed that it might be tested. As seen in the figure below, when Anthropic inhibited internal representations related to evaluation awareness[3], its misaligned behavior rate on synthetic honeypot tests increased from 0% to between 1% and 9%. This effect was [...]
---
Outline:
(06:58) Sonnet 4.5 is much more evaluation-aware than prior models
(10:00) Evaluation awareness seems to suppress misaligned behavior
(14:52) Anthropic's training plausibly caused Sonnet 4.5 to game evaluations
(16:28) Evaluation gaming is plausibly a large fraction of the effect of training against misaligned behaviors
(22:57) Suppressing evidence of misalignment in evaluation gamers is concerning
(25:25) What AI companies should do
(30:02) Appendix
The original text contained 21 footnotes which were omitted from this narration.
---
First published:
October 30th, 2025
Source:
https://www.lesswrong.com/posts/qgehQxiTXj53X49mM/sonnet-4-5-s-eval-gaming-seriously-undermines-alignment
---
Narrated by TYPE III AUDIO.
---
Popular Podcasts
Stuff You Should Know
If you've ever wanted to know about champagne, satanism, the Stonewall Uprising, chaos theory, LSD, El Nino, true crime and Rosa Parks, then look no further. Josh and Chuck have you covered.
Las Culturistas with Matt Rogers and Bowen Yang
Ding dong! Join your culture consultants, Matt Rogers and Bowen Yang, on an unforgettable journey into the beating heart of CULTURE. Alongside sizzling special guests, they GET INTO the hottest pop-culture moments of the day and the formative cultural experiences that turned them into Culturistas. Produced by the Big Money Players Network and iHeartRadio.
Dateline NBC
Current and classic episodes, featuring compelling true-crime mysteries, powerful documentaries and in-depth investigations. Follow now to get the latest episodes of Dateline NBC completely free, or subscribe to Dateline Premium for ad-free listening and exclusive bonus content: DatelinePremium.com